陈道一,12/14/2023
MoE的发明的动机是什么?
MoE提出自hinton 1991年的论文Adaptive mixtures of local experts,主要目的是加快模型训练的速度。因为正常训练过程中,如果使用同一个网络去拟合全部的数据,因为数据是多样性的,所以拟合的过程会比较慢。这时候如果有多个专家网络,每个专家网络只拟合一部分的数据,那么模型整体的学习速度以及泛化的能力都会增强。
第一次将MoE应用到transformer中的工作是Google 2021年的GShard,并且确定了最近几年MoE工作的主要动机:保持相同训练和推理资源的同时,通过增加模型的体积代价来提升模型学习效果。
为什么在1991年提出直到最近才重新进入视野?
1991年还处在BP算法刚刚提出来的阶段,最优的模型也就是多层感知机。当模型本身的容量较低的时候,在复杂的场景下,用一个网络去拟合所有的数据,会因为数据的多样性,所以拟合的过程会比较慢。所以MoE被提出用来增加模型在复杂场景下学习的效果,虽然在LLM时代,只要有足够的算力和数据,模型规模扩大一定能带来更好的效果。但在当时的算力稀缺并且缺少模型scaleup需要的技术时,这种方法还是可以提高参数利用率的。
而当LLM发展到GPT3的规模,推理和训练对应的优化方法也趋近于完善,继续scale up更多依赖于硬件的提升。那么当算力发展变缓或者获取成本变高的时候,就需要另外一种可以继续scale up但不那么依赖于硬件的方式,MoE开始进入人们的视野。
MoE为什么会起作用?
scaling law层面的解释
Scaling laws for neural language models揭示了模型规模、数据大小、以及算力大小之间的规律,并且建议对算力最佳利用方式是:在固定数据集大小下 尽量训练更大规模的模型。这里的规模一般指的是模型参数数量 以及 需要的计算量,参数量增加同时计算量也会增加。
MoE相当于一次解耦,只增加模型参数数量、同时保持需求计算量相对恒定,所以效果提升符合scaling law的规律。
典型的MoE在transformer结构中应用如下(switch-transformer, Google, Jul 2022):
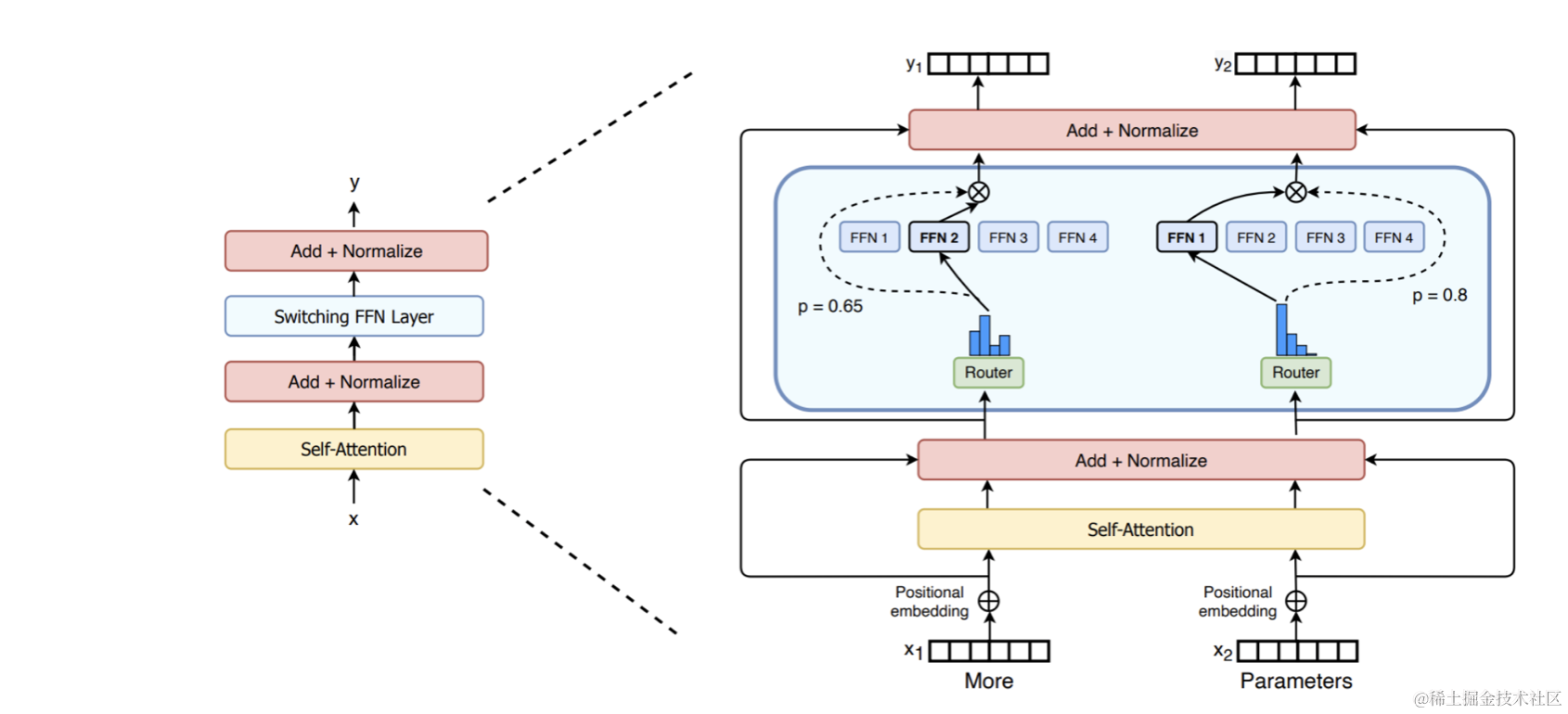
模型结构层面的猜想
观察1:FFN可以理解为KV对,K代表了文本模式、V代表了文本分布^[1]^,越靠后的层学习到越复杂的模式。
观察2:模型越靠后的层学习越不够充分。
基于这2个观察,可以做出一个假设:学习不充分的原因是容量不够,越靠后的层对容量需求越大。支撑这个假设的一个实验观察是:如果只有一个MoE层,放在越靠后的位置,最终效果越好^[3],[4]^。另外,从直觉上复杂的模式对应的数量是简单模式的指数倍,需要更多的参数去拟合。
所以MoE通过增加FFN的数量,增加了模型的容量,可以学习到更多的文本模式,所以得到更好的效果。
[1] Transformer Feed-Forward Layers Are Key-Value Memories [2] Deepspeed-MoE#PR-MoE [3] Hash Layers For Large Sparse Models#Figure 3
Expert真的是专家吗?
考虑下面3个MoE路由配置的实验:
- 将语义相似的token路由到相同的expert上;
- 将语义相似的token路由到不同的expert上;
- 随机将token指定到一个固定的expert上;
如果把expert理解成不同领域的专家,那么应该是1>2>3,但真实的实验结论是2>3»1(23.22>23.27»23.99)。
对此一个合理的解释是:experts并不是理解中的”领域专家“ 分别学习不同的领域知识,而是增加对相似文本模式之间的区分度;相似的文本模式更可能发生在相似的token上面,所以相似的token应该路由到不同的expert上。
如何计算训练和推理成本?
结论1:MoE训练所需的显存与基底模型并没有明显差别;
以Mixtral-7B*8 MoE为例:
| dim | n_layers | hidden_dim | n_heads | n_kv_heads | vocab_size | num_experts_per_tok | num_experts |
|---|---|---|---|---|---|---|---|
| 4096 | 32 | 14336 | 32 | 8 | 32000 | 2 | 8 |
- 整体参数量:46b
- 活跃参数量:12b
- 对应基底模型参数量:7.2b
计算过程如下:
- transformers:
- FFNs: 176,160,768 * 8 = 45,097,156,608
- gate: 4096 * 8 = 1,048,576
- MA: 4096 * (128 * 48) + 4096 * 4096= 41,943,040
- LN: 4096 * 2 = 8,192
- total: (176,160,768 * 8 + 41,943,040 + 8,192 + 4096 * 8) * 32 = 46,440,644,608
- others:
- embed & output_w: 262,144,000
- total:
- 46,440,644,608 + 262,144,000 = 46,702,788,608 = 46B
- active params:
- (176,160,768 * 2 + 41,943,040 + 8,192 + 4096 * 8) * 32 + 262,144,000 = 12,879,921,152 = 12.8B
模型训练的并行方式分为3种,DP(data parallel) / TP(tensor parallel) / PP(pipline parallel),MoE模型在训练时可以同时使用这3种模型外,还可以加入EP(expert parallel)方式。EP的精髓就是多个模型中共享expert,2点理解:
- 因为MoE每次前向中只用到一小部分expert,如果每个模型保留完整的expert,一定会导致大多数expert空闲的情况;
- 如果DP是8,EP是2,那么2个模型共用一套完整的experts;
训练并行设定:TP2 DP8 EP8 (megatron方案),需要显存如下:
| module | MoE参数/单卡 | Dense参数/单卡 |
|---|---|---|
| Emb and Output | $h * vocab *2 /TP$=262 144 | $h * vocab *2 /TP$=262 144 |
| experts | $hffn3 * num_experts * n_layers / TP / EP$=88 080 384 | $hffn3 * n_layers / TP$=88 080 384 |
| gate | $h*num_experts * n_layers$=1 048 576 | / |
| GQA | $hhdim(nhead+n_kv_heads) * 2 * n_layers / TP$=671 088 640 | $hhdim(nhead+n_kv_heads) * 2 * n_layers / TP$=671 088 640 |
| LN | $h*2 * n_layers$=262 144 | $h*2 * n_layers$=262 144 |
| total | 3,622,043,648 | 3,620,995,072 |
| 推理所需显存/单卡 | 7,244,087,296 | 7,241,990,144 |
| 训练所需显存/单卡 | 57,952,698,368 | 57,935,921,152 |
通过加入EP的方式,在7B的模型大小下,MoE训练所需的显存于正常7B相差不大,结论成立。
注:实际计算中,MoE 的激活值会相比原有增大 EP 倍,和训练长度有关,以实际为准。
结论2:expert数量越多,训练时所需的最小设备数越多;
不超过7B的情况下,最小设备数的计算的逻辑如下:
- 确定了训练使用设备的GPU显存大小,以及基底模型规模; 比如:80G,7B
- 确定可以使用的最小TP(tensor parallel)数; 因为每张卡上可以训练的参数量差不多是3-4B,因此TP=2的时候满足要求,每张卡3.5B;
- EP(expert parallel)使用最大,以节约内存; EP = num_experts
- 因为expert在DP中共享,所以DP必须是EP的整数倍; DP=EP
- 最终,最小设备数为:DP * TP。
在7B情况下,num_experts=8 最小设备数为16、num_experts=16 最小设备数为32。
在Mixtral-7Bx8 MoE的例子中,训练时可以跑起来的最小硬件要求:A100 80G x 8张 x 2台。
注1:超过7B时,必须要使用PP才能训练。
注2:模型较大的情况下,还需要考虑稳定性其他因素,最优的并行组合需要实测后才能得出;
训练成本
刨除显存以及设备数量这2点因素,训练成本以及速度计算如下:
- 差异主要来自推理过程中活跃参数的数量差异;
- MoE 7b*8 的活跃参数是12b,所需算力相当于训练12b模型所需的算力;
推理成本
以Mixtral-7Bx8为例,整体参数量为46b,活跃参数是12b,但是在并行条件下推理速度接近于7.2b基底模型。因为虽然模型计算量翻倍了,但是模型容量主要是由宽度带来的,wide model更利于并行计算。
但是由于计算量增加,所以在固定设备数量的前提下,对外服务的最大吞吐量会减半。也就是说:
- MoE模型会降低推理系统的最大吞吐量,但是时延变化不大;
- 吞吐量降低多少主要与活跃参数相关。
Mixtral-7Bx8MoE的收益和成本?
成本
成本主要取决于推理过程种的活跃参数,Mistral 7Bx8的MoE模型每次推理使用2个expert(top2),所以训练成本大概相当于7B模型的2倍,既训练一个12B模型所需的算力资源。
收益
| Model | active params | MMLU | HellaS | WinoG | PIQA | Arc-e | Arc-c | NQ | TriQA | HumanE | MBPP | Math | GSM8K |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaMA 2 7B | 7b | 44.4 | 77.1 | 69.5 | 77.9 | 68.7 | 43.2 | 17.5 | 56.6 | 11.6 | 26.1 | 3.9 | 16.0 |
| LLaMA 2 13B | 13b | 55.6 | 80.7 | 72.9 | 80.8 | 75.2 | 48.8 | 16.7 | 64.0 | 18.9 | 58.4 | 6.0 | 34.3 |
| LLaMA 2 33B | 33b | 56.8 | 83.7 | 76.2 | 82.2 | 79.6 | 54.4 | 24.1 | 68.5 | 25.0 | 40.9 | 8.4 | 44.1 |
| LLaMA 2 70B | 70B | 69.9 | 85.4 | 80.4 | 82.6 | 79.9 | 56.5 | 25.4 | 73.0 | 29.3 | 49.8 | 13.8 | 69.6 |
| Mixtral 7B | 7B | 62.5 | 81.0 | 81.0 | 82.2 | 80.5 | 54.9 | 23.2 | 62.5 | 26.2 | 50.2 | 12.7 | 50.0 |
| Mistral 8x7B | 12B | 70.6 | 84.4 | 84.4 | 83.6 | 83.1 | 59.7 | 30.6 | 71.5 | 40.2 | 60.7 | 28.4 | 74.4 |
- Mixtral 7B -> MoE 7Bx8,上涨15.6%;
- LLaMA 7B -> 13B,上涨19.4%;
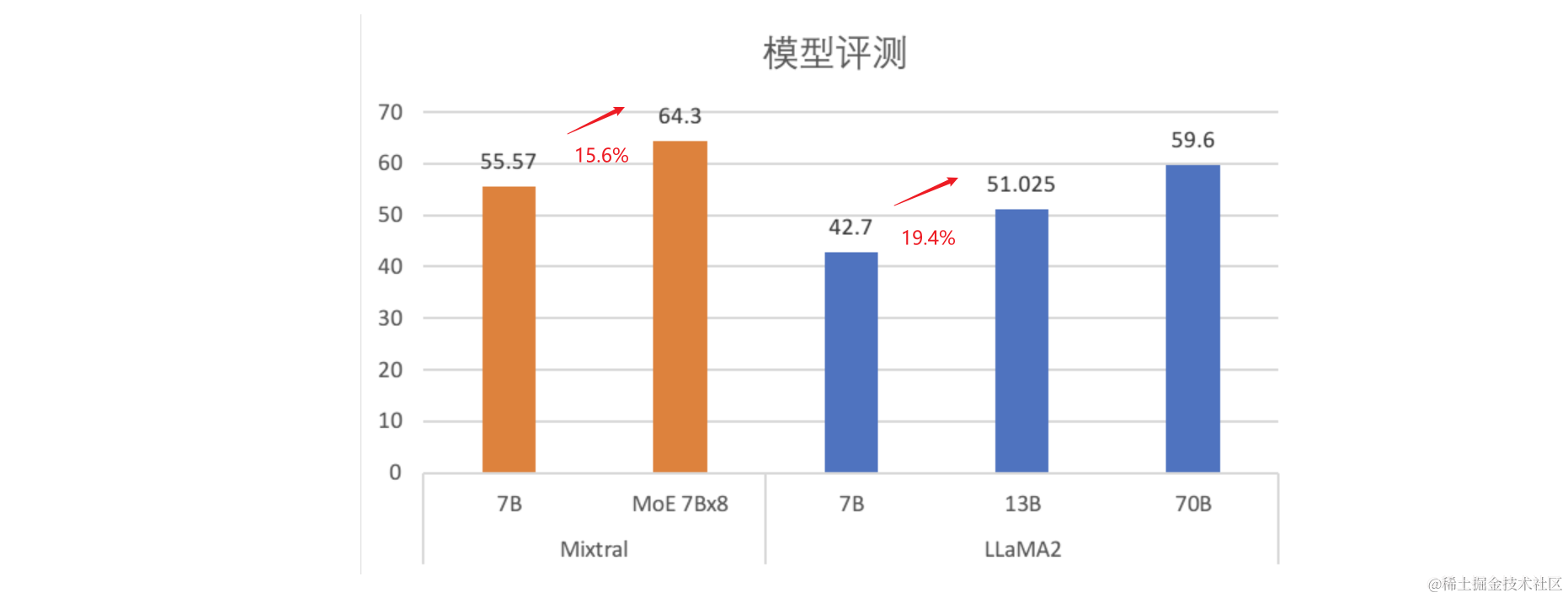
结论:考虑到分数越高越难提升,mixtral的MoE 7Bx8的效果收益可以认为与直接训练13B的模型相仿。
数据来自:Mixtral of experts | Mistral AI | Open source models
MoE应用场景与对应的收益成本
*基础要求:建议的模型方案,所消耗的算力与基底模型保持不变。
注:Switch-transformers, HashMoE, DeepspeedMoE等论文中的方案都可以满足该要求。
场景一:在模型规模扩大遇到瓶颈时,通过MoE继续提升模型效果,并且使用保持相同的算力资源。
收益:
- 10%以上的效果提升; 类比mixtral 7bx8 MoE提升15%,GPT4比GPT3提升 20+%
成本:
- 没有明显的成本增加;
场景二:对于线上模型,可以替换为更小基底的MoE模型。
收益:
- 在相同的推理资源下,维持相同的最大吞吐量,并大大降低模型的时延;
- 小基底的MoE模型使用的训练资源更少。
成本:
- 没有明显的成本增加,除了开发的复杂度变高;
MoE有哪些重要的工作
| 时间 | 单位 | 模型名称 | gating | sparsity | Arch |
|---|---|---|---|---|---|
| Jun 2020 | GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding 引用:543 | learnable token-based | top2 | MA>MoE>MA>FFN | |
| Jun 2021 | Switch-transformers引用:1024 | learnable token-based | top1 | MA>MoE | |
| Jul 2021 | FAIR | Hash Layers For Large Sparse Models引用:95 | determinative hash-based | *top1(hash决定) | MA>MoE |
| Apr 2022 | Google Brain | ST-MoE: DesigningStable and Transferable Sparse Expert Models引用:28 | learnable token-based | top2 | [MA>FFN]*3 >MA>MoE |
| Aug 2022 | GLaM: Efficient Scaling of Language Models with Mixture-of-Experts引用:240 | learnable token-based | top2 | MA>MoE>MA>FFN | |
| Oct 2022 | Mixture-of-Experts with Expert Choice Routing引用:56 | learnable expert-based | top2 | MA>MoE | |
| Oct 2022 | University of Texas | Residual Mixture of Experts引用:19 | core + residual | Top2 | MA>RMoE |
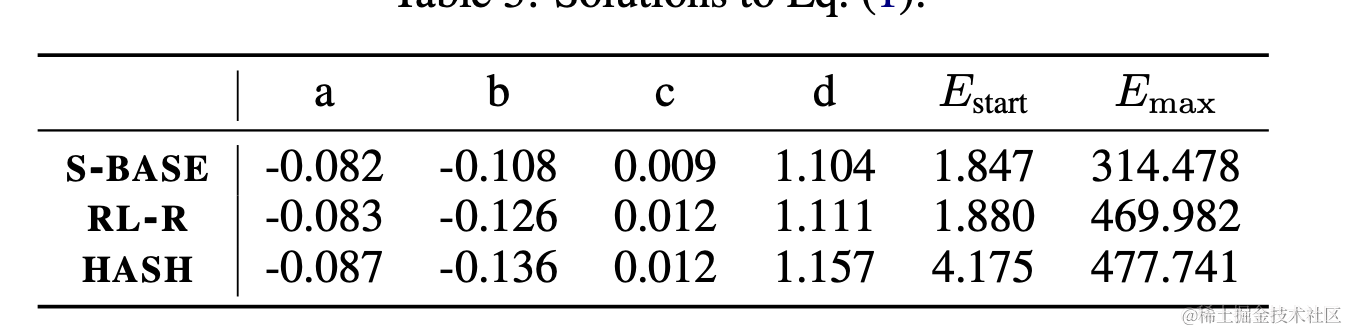
MoE的scaling law:
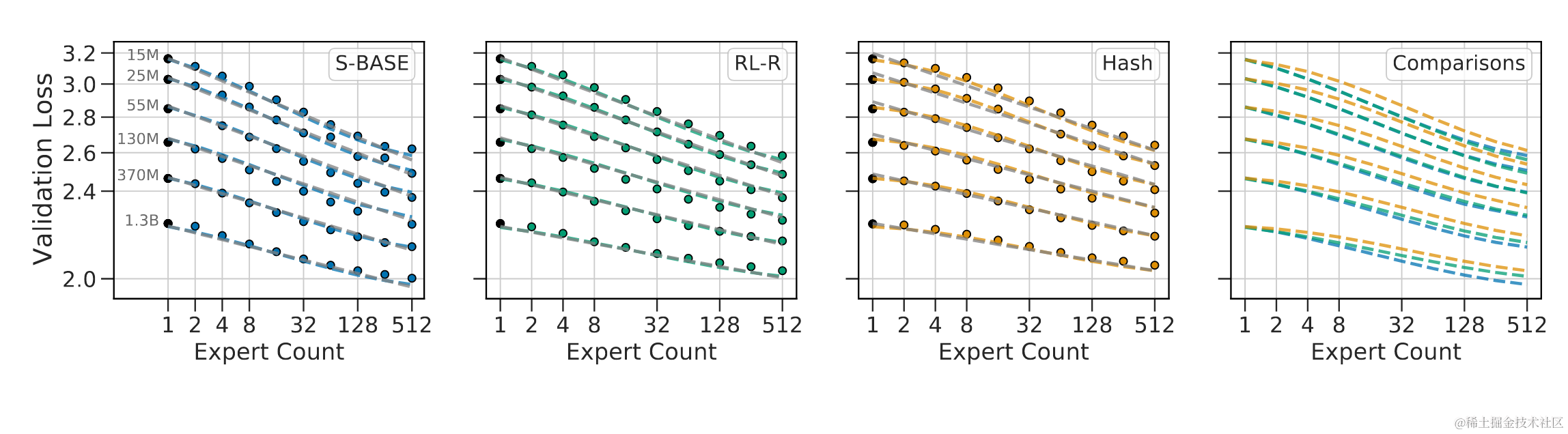 来自 Deepmind, 2022, Unified Scaling Laws for Routed Language Models
来自 Deepmind, 2022, Unified Scaling Laws for Routed Language Models
计算公式如下:
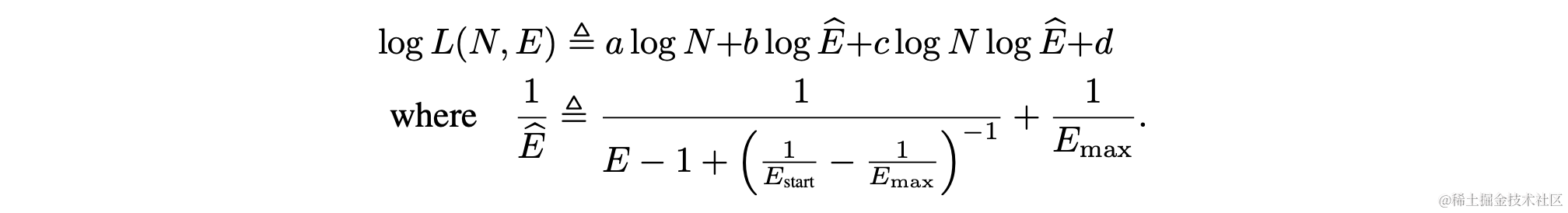
需要注意的有以下几点:
log的基底为10;
默认MoE的位置是 MA->FFN->MA->MoE;
也就是隔一层放置一个,如果是每层放置,对应的expert数量要*2;
对应的参数有3组,分别对应了3种路由算法:S-BASE、RL-R、HASH;
其中Hash效果最差,与self-learning参数的路由最接近;
mega-blocks对应的方案是S-BASE的方案,效果最好;所以如果只是使用的话注意选择合适的参数;
一个scaling law的使用场景是计算有效参数,能够把MoE的模型参数对应到对应的Dense网络参数,计算方式如下:
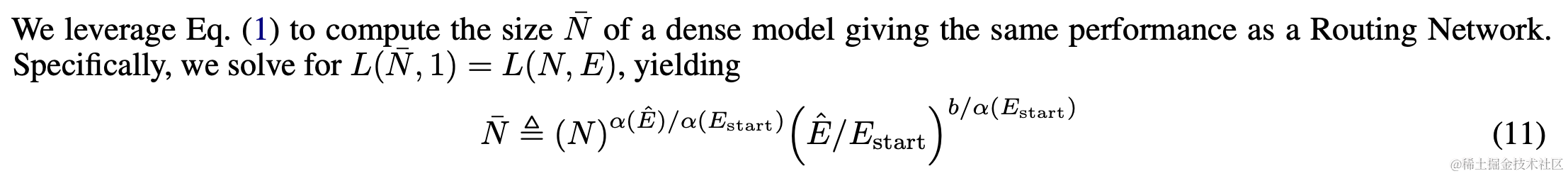
实测,Mixtral 7bx8对应的有效参数大小是12.2B,与前面从效果和算力层面的推测一致。
难收敛如何解决
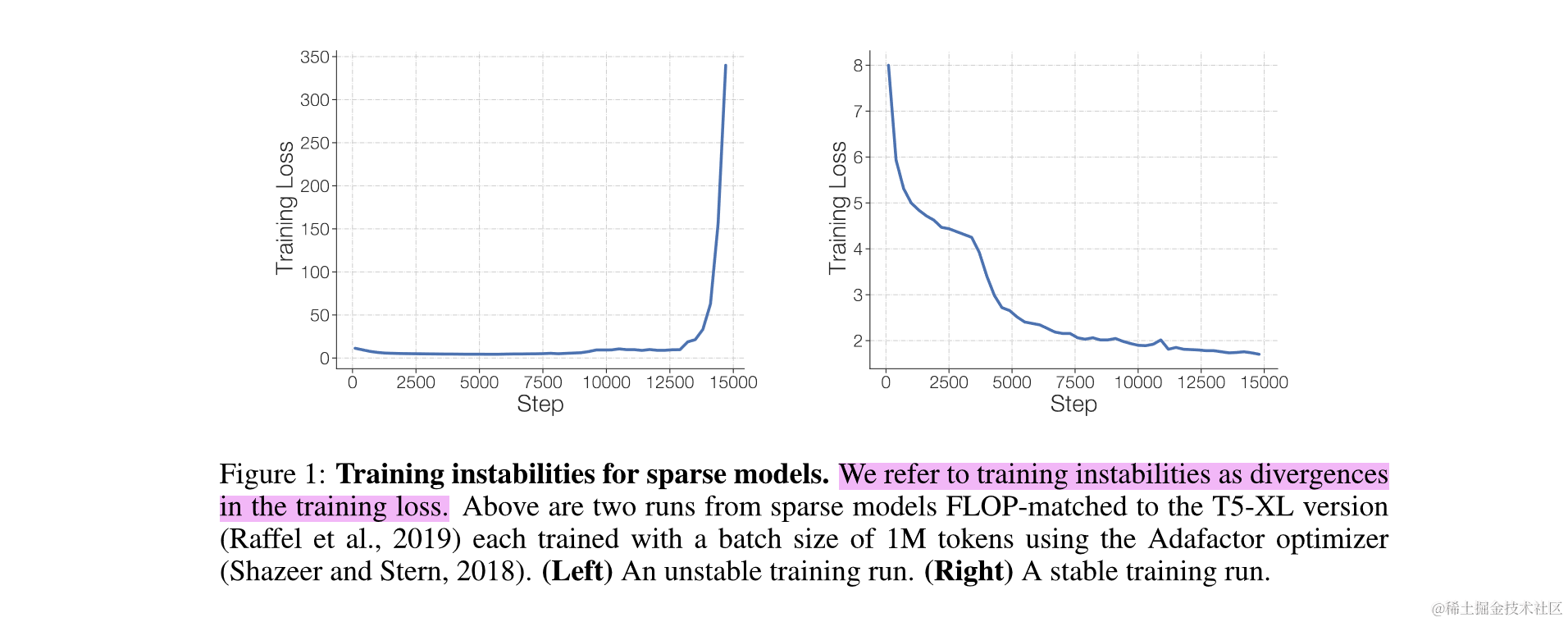
原因1:MoE刚开始训练时expert是随机初始化的,并且训练过程中expert的能力在不断变化,所以初期gating网络一直在拟合变化中的mapping关系,导致收敛时间边长;
解决方法1:分阶段训练;Evo-MoE
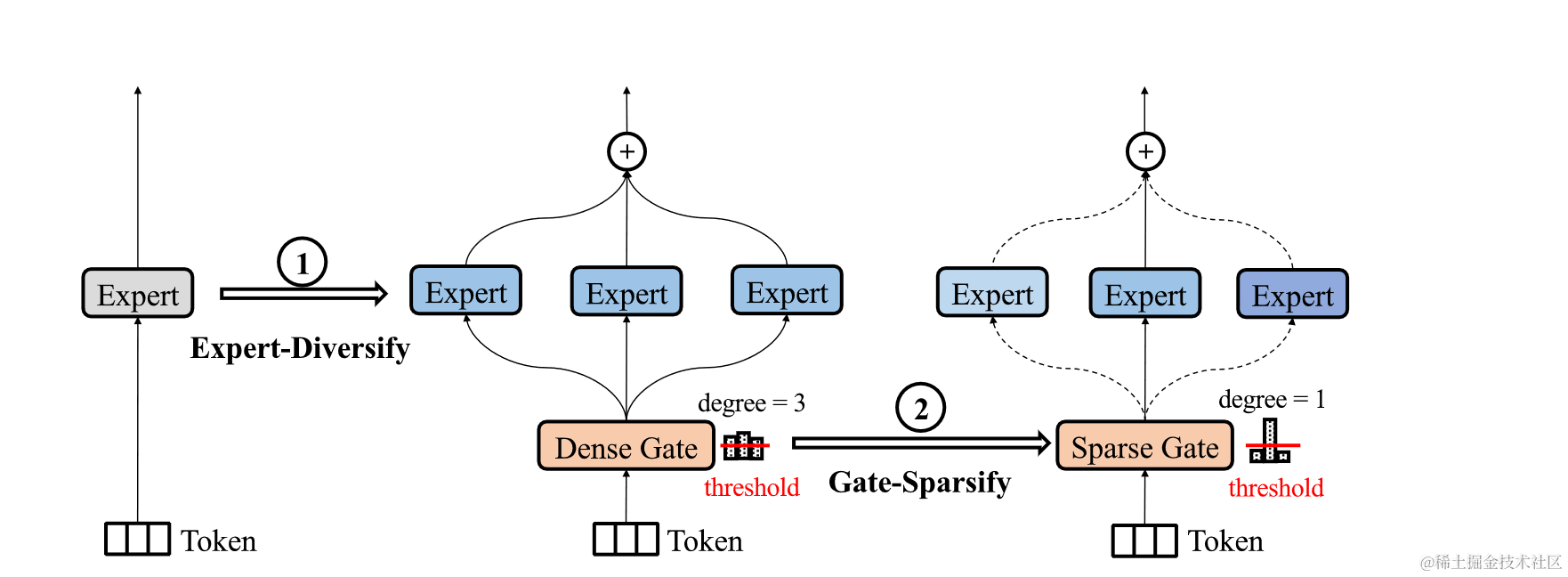
a. 首先训练一个正常的网络;b. 通过随机mask将expert分化成不同的expert;c. 加入gating网络,从topk逐渐降低到top1;
解决方法2:使用固定的映射作为route,hash-based routing。
这种方式可以提前生成token对应的expert映射,所以不存在波动的问题。
原因2:gating网络数值不稳定性;
gating网络在更新时,输入的logits会增大。因为softmax的导数与输入成正比,所以输入越大会导致梯度越大,容易产生不稳定。
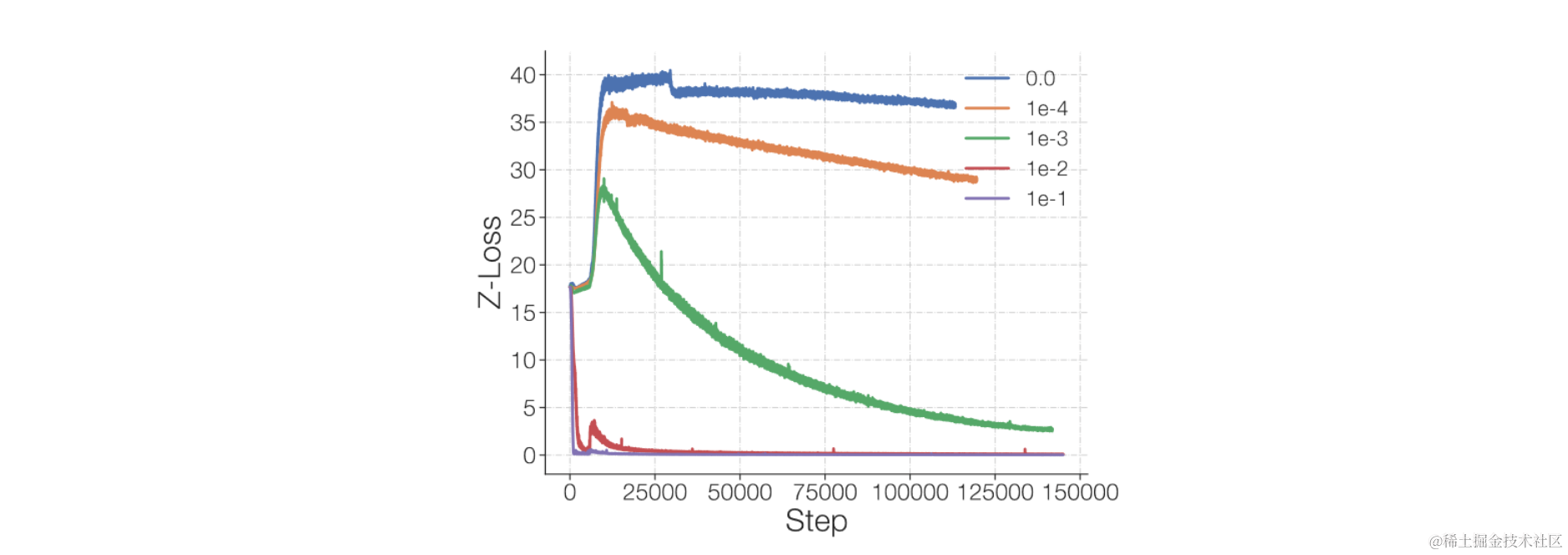
解决方法:加入z-loss,限制输入gating网络的logits的大小。

其他原因:
- 乘性算子:RMS LN、GEGLU使用会增加不稳定性;
- 越大的模型越不稳定;
相关解决方法:
- float32去计算gating 网络中的softmax;
- 使用更小的初始化参数;
expert负载均衡如何解决?
问题提出:Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
We have observed that the gating network tends to converge to a state where it always produces large weights for the same few experts;
如果不做任何控制,gating网络会倾向于给某几个expert更高的权重。
少量的负载不均衡不会影响模型效果,但是会影响推理和训练的速度。
解决方法:
- 附加损失auxiliary loss
- hash-based route
微调效果不稳定如何解决?
问题原因:
- MoE模型比Dense模型更容易在少量数据上过拟合;
- MoE参数微调容易带来基础性能的丢失;
解决方法:
- expert dropout调整到比正常参数高一些; 正常0.1,expert 0.4
- 只更新非expert参数往往能够得到和全量更新同样的效果。
附录
相关论文速览
Adaptive mixtures of local experts
Hinton, 1991 https://direct.mit.edu/neco/article/3/1/79-87/5560
这篇论文第一次介绍moe的方法,其主要目的是加快模型训练的速度。因为正常训练过程中,如果使用同一个网络去拟合全部的数据,因为数据是多样性的,所以拟合的过程会比较慢。这时候如果有多个专家网络,每个专家网络只拟合一部分的数据,那么模型整体的学习速度以及泛化的能力都会增强。
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
Google, Jun 2022 http://arxiv.org/abs/2101.03961
目的还是把模型做大,容量提升 但是不明显增加推理的计算量。论文主要围绕3个问题提出解决方案:复杂度、通讯消耗、训练稳定性。实验基于T5家族模型上进行,第一次证明了这类稀疏模型可以用低精度(BF16)训练。最终效果,同样的资源情况下训练速度提升4-7倍,在多语种场景下在全部101种语言上观察到提升。
Balancing has been previously shown to be important for training MoE models!
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
Google, Aug 2022 http://arxiv.org/abs/2112.06905
第一次将MoE应用到GPT3这种规格的模型上面,最终的效果也是在29个NLP任务中领先GPT3。最大的模型参数量是GPT3的7倍,但是训练消耗仅仅是1/3。有趣的是,他们用训练使用能量来衡量训练消耗。
**PS:**虽然模型结构和GShard完全类似,但是应用规模比其他的工作要大,所以有较高的参考价值。
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Google, 2021 https://arxiv.org/pdf/2006.16668.pdf
第一次将MoE应用到transformer结构中,并且介绍了很多工程的细节,比如并行 以及 负载均衡。在工程方面,提出了一套API来处理MoE高效并行的实现,将模型结构和具体实现分离,并且在使用起来更符合语义层面的理解。值得深入研究,对工程实现方面的借鉴意义更大。
Brainformers: Trading Simplicity for Efficiency
Deepmind, 2023 http://arxiv.org/abs/2306.00008
提出一种新的FFN、Attn、Gate模块的排列方式,比正常的attention排列得到的模型更高效(原文quality and efficiency)。与同是MoE模型的GLaM相比,提升2倍的收敛速度,降低5倍的单步训练时长。
新的模型结构通过自动化程序挖掘出来;top-2 has demonstrated stronger empirical performance than top-1 gating;
To avoid causal leakage in decoding mode, we suggest normalizing along the expert dimension for both token-based routing and expert-based routing. 因为在训练的过程中,其实是用全文做的normalize,但是decode的时候看不到全文。
问题:在Token-based Routing Versus Expert-based Routing这章节里,为什么要做normalize?
ST-MoE: Designing Stable and Transferable Sparse Expert Models
Google Brain, Apr 2022 http://arxiv.org/abs/2202.08906
主要针对MoE模型的训练稳定性,以及微调质量无法保证 这2个问题,提出了对应的解决方案,最终得到的模型叫做ST-MoE-32B。效果层面上,通过微调的MoE模型第一次在下游任务中得到SoTA。
主要通过模型结构以及loss的改动,增加训练的稳定性。并且对训练稳定性进行了深入的研究,定量分析了一些模型改动对稳定性的影响。可能是对MoE训练稳定性问题研究最多的一篇论文。
Mixture-of-Experts with Expert Choice Routing
Google, Oct 2022 https://arxiv.org/pdf/2202.09368.pdf
文章的动机是解决不好的routing策略,导致expert训练不充分的问题。不同于正常的routing策略是token选择experts,本文中提出的策略是expert选择tokens。对比了Switch Transformer和GShard 2种方法,发现训练速度可以提高1倍,并且效果GLUE和SuperGLUE上表现更好。
第一次提出expert-based routing的方式,后来在BrainFormer中有被用到。为什么这种方式会更好呢,背后的直觉是什么?
From Sparse to Soft Mixtures of Experts
Google Deepmind, Aug 2023 http://arxiv.org/abs/2308.00951
视觉方向的一篇MoE论文,主要解决的问题是:训练不稳定、token dropping、experts扩展、微调效果。提出一种完全可导的稀疏MoE结构(==正常的MoE不是也可导吗?==)本质上,这篇文章也提出了一种新的Routing策略,对比了Token-based和Expert-based这2种routing策略,在推理速度、expert数量扩展上都有不同程度的优势。
Hash layers for large sparse models
Facebook AI, Jul 2021 http://arxiv.org/abs/2106.04426
通过对token Hash选择expert,省去了gating网络,优于SwitchTransformer和传统的Transformer模型。同时探索了不同的hash算法对应的效果,并且分析hashing-routing方法的有效性。
感觉上Hash方法更接近于随机去选择expert,为什么还能起到效果,很奇怪?Hash如何与语义关联的?
正常的gating网络和expert需要一起进行训练,而在刚开始的时候gating网络是随机的,expert之间也没有什么区别,那么随着expert不断训练它所包含的知识也在改变,而gating网络去学习这种变化的mapping关系,可能会导致模型最后效果很差。PS:本质上还是如何将expert训练的更有差异化的问题。基于这个问题,这篇文章提出的hashing至少在训练过程中会更稳定,确定了hash算法,那么token和expert之间的mapping关系就定下来了。PS:直觉上可以加快模型训练的速度。
这篇论文实验非常详细,感觉对于routing策略来说是一个很强的baseline。结论说明一点,固定的routing方法能得到更好的训练结果
Go Wider Instead of Deeper
National University of Singapore, Sep 2021 http://arxiv.org/abs/2107.11817
MOE模型虽然保证计算量不增加太多,但是模型占用显存是显著增加了的。这篇论文中通过层间共享参数的机制,降低了显存的占用,并且得到的效果还不错(类似ALBERT结合MOE)。
把ALBERT中层共享参数的方法与MoE模型,然后声称是Wider Net。然而,计算过程还是会有多层的推理,每一层的layer norm使用的是不同的参数。有点标题党的嫌疑,并且测试模型的规模都比较小,没有太多可以借鉴的地方。
Adaptive mixtures of local experts论文阅读
BP提出自1986年,这篇文章写自1991年。
主要想解决的问题是:当BP用来训练一个解决多个不同问题的网络时,因为任务之间的干涉导致模型难以收敛和泛化。虽然在LLM时代,只要有足够的算力和数据,模型规模扩大一定能带来更好的效果。但在当时的算力稀缺并且缺少模型scaleup需要的技术时,这种方法还是可以提高参数利用率的。
原来的公式:
$$ \mathbb{E}^c = {\parallel \vec{d^c}-\sum_i{p_i^c \vec{o_i^c}} \parallel}^2 $$
其中,$c$ 是case,$d$是目标输出,$p$ 是expert对应的gate weight,$o$ 是export对应的输出。
分析:如果其中1个expert的输出($o_i$)改变,导致expert所有输出的调和超过了最终的输出($\vec{d^c}$),那么所有expert梯度都会变为反方向。造成的结果就是,expert之间会互相干扰,导致收敛速度变慢,并且学习到的expert会倾向于合作的关系,共同作用于1个case并得到最终结果。
那么有没有方法expert之间更倾向于竞争关系呢。
这个问题有2篇相关的论文:
- Learning piecewise control strategies inamo dular connectionist architecture
- Task decomposition through competition in a modular connectionist architecture: The what and where vision tasks
==TODO==:一种方法是给目标函数添加惩罚项,来奖励expert之间更多的竞争。
如果把loss改成如下:
$$ \mathbb{E}^c = \sum_i p_i^c{\parallel \vec{d^c}-\vec{o_i^c} \parallel}^2 $$
最直观的变化是,每个expert的输出单独拿出来和目标进行比较,所以不管gate网络和其他网络的输出是什么,每个expert得到的梯度方向只取决于自身的输出和目标的差值。但如果其中某个expert输出对应的error变小,那么gate网络对应该expert的概率就会增加。这点可以通过梯度 $\frac{\partial \mathbb{E}^c}{p_i}={\parallel \vec{d^c}-\vec{o_i^c} \parallel}^2$很明显的看到,$p_i$梯度大小取决于error平方的大小,梯度越大下降的越快。
新的目标函数对应每个expert的梯度如下:
$$ \frac{\partial \mathbb{E}^c}{\partial \vec{o_i^c}}=-2p_i^c(\vec{d^c}-\vec{o_i^c}) $$
此时会出现一个问题,当初期网络随机初始化后,可以认为每个expert对应的权重$p_i^c$是相同的,那么每个expert的梯度取决于error的大小,所以拟合最好的expert得到的梯度最小。为了解决这个问题,提出了新的目标函数如下:
$$ \mathbb{E}^c=-log\sum_i{p_i^c e^{-\frac12\parallel \vec{d^c}-\vec{o_i^c} \parallel^2}} $$
此时每个expert输出对应的梯度为:
$$ \frac{\partial \mathbb{E}^c}{\partial \vec{o_i^c}}=-\Big \frac{p_i^c e ^{-\frac12\parallel \vec{d^c}-\vec{o_i^c} \parallel^2}}{\sum_j{p_j^c e ^{-\frac12\parallel \vec{d^c}-\vec{o_j^c} \parallel^2}}} \Big $$
梯度的前部分确保了表现好的expert能够得到更快的训练。